
Google Geminiは、Google社が開発した最新の生成AIモデルです。2023年12月7日にGoogle社から発表され、話題の生成AIモデルですが、「Google Geminiについてよく理解していない」という企業担当者も多いのではないでしょうか。
そこで今回は、Google Gemini の特徴やできること、GPT-4との違いなどについて解説します。
Google Geminiとは?

©rimidolove/123RF.COM
Google Geminiとは、Google社が開発した最新の生成AIモデルです。マルチモーダル型の生成AIという特徴を持ち、テキストや画像、音声、動画などの生成処理を別々に行い、最後に各データをつなぎ合わせることでスムーズなアウトプットの作成が可能となっています。
Google Geminiには、以下の3つのモデルがあります。
- Nano:デバイス上のタスクに最も効率的なモデル
- Pro:幅広いタスクに対応する最良のモデル
- Ultra:非常に複雑なタスクに対応する、高性能かつ最大のモデル
Gemini Proは2023年12月よりGoogle Bardの英語版に搭載され、Gemini Nanoは2023年10月より発売されたスマートフォン「Pixel 8 Pro」に搭載されています。Gemini Ultraは2024年にリリースされる予定です。
Google Geminiでできること
ここでは、Google Geminiでできることとして、以下の項目についてGoogle公式のデモ動画を用いながら解説していきます。なお、Google公式のデモ動画は実演場面を切り出した静止画をまとめたものとなっているため、あくまで参考イメージとしてご確認ください。
- 動画の内容を認識できる
- 音声と画像を同時に認識できる
- 画像を認識して問題点を抽出できる
- 画像を認識してコード化できる
- 画像や記号を基に推測できる
動画の内容を認識できる
Google Geminiは、動画の内容を認識してテキストで回答することが可能です。たとえば、以下のように鳥の絵を紙に書いている動画をGoogle Geminiに見せると、「It looks like a bird to me」(私には鳥のように見えます)と回答が返ってきます。
その後、紙の中央に波線を追加すると、「The bird is swimming in the water」(鳥が水の中を泳いでいます)と追加で回答されました。このようにGoogle Geminiは、動画内のコンテンツを捉えながら動画に合った内容をテキストで説明することが可能です。
音声と画像を同時に認識できる
Google Geminiは、音声と画像を同時に認識することもできます。たとえば、音声で「この材料で野菜オムレツを作るときの最初の手順は何?」と質問し、野菜が入ったボウルと卵の画像を貼り付けました。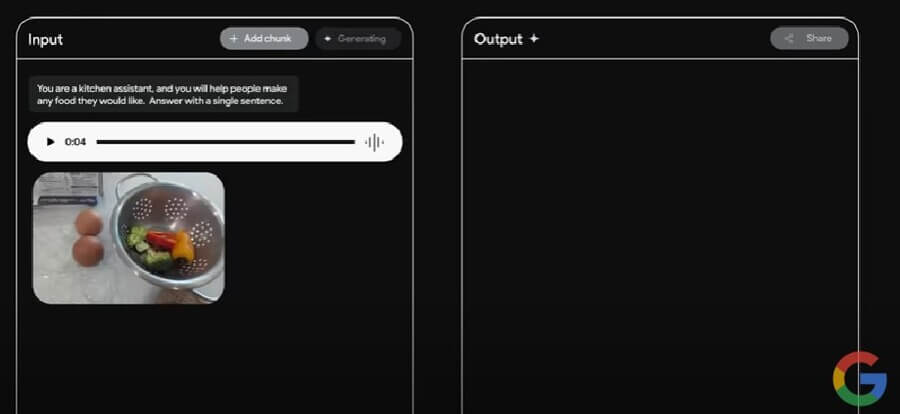
その結果、Google Geminiから「ボウルに卵を割って溶きます」との音声回答が得られました。このことから、Google Geminiが音声と画像の両方を認識できることが分かるでしょう。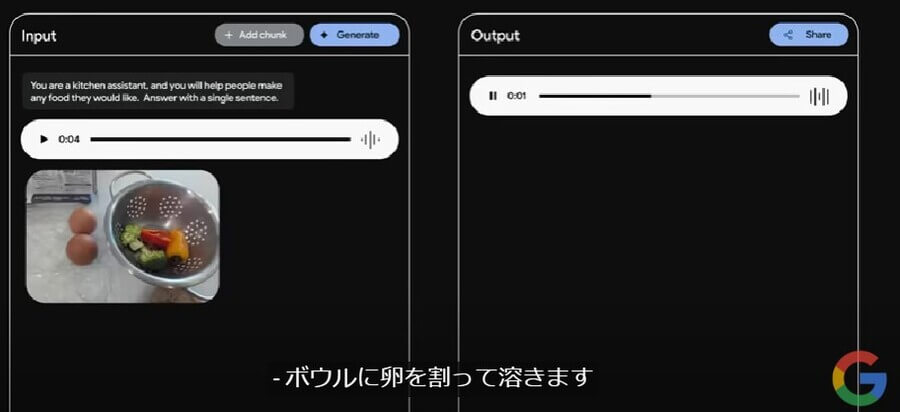
その後、質問者がオムレツを作り始め、「これで完成ですか?」と音声で質問しながらオムレツの調理画像を追加で貼り付けます。すると下のとおり、Google Geminiから「ほぼ完成のようです。ひっくり返して反対側も焼いてください」との音声回答が得られました。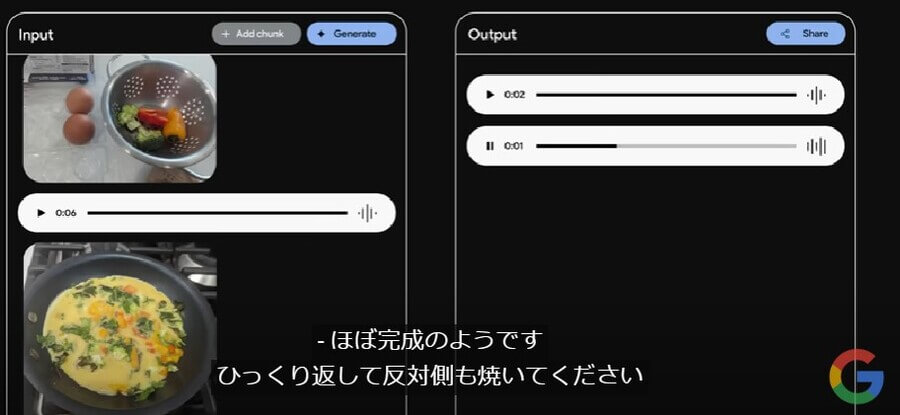
画像を認識して問題点を抽出できる
Google Geminiでは、画像の中身を認識して画像内にある問題点を抽出することも可能です。たとえば、数学などの問題において手書きの答案をアップロードすると、下図のようにGoogle Geminiが内容を解析して答えの添削をしてくれます。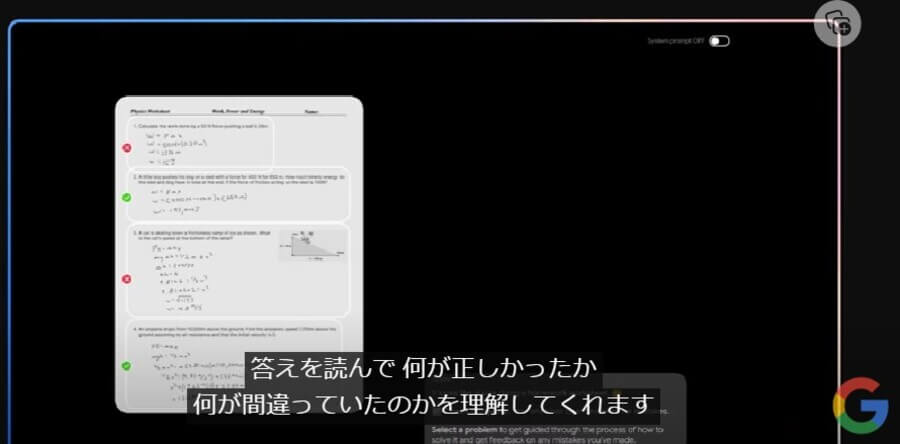
加えて、不正解となった回答がなぜ間違っていたのかについて、原因を特定して解説を行うことも可能です。以下では、問題を解くための公式は正しかったものの、高さの計算で間違いがあったことをGoogle Geminiが検出しています。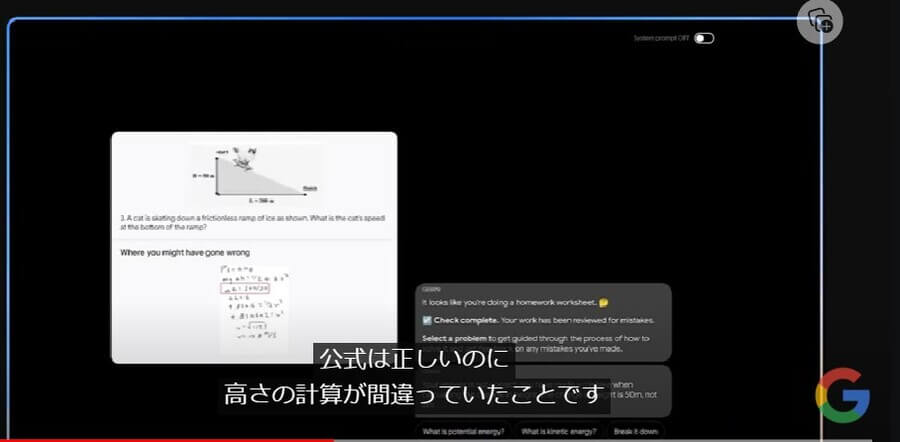
画像を認識してコード化できる
Google Geminiは、画像を認識してプログラミングコードに変換することも可能です。たとえばGoogle公式のデモでは、下のような木の画像をコードに変換する作業を紹介しています。
このデモでは、Google Geminiにプロンプトを入力し、以下のように木の画像を基にしたフラクタル構造の木の図形を作成しています。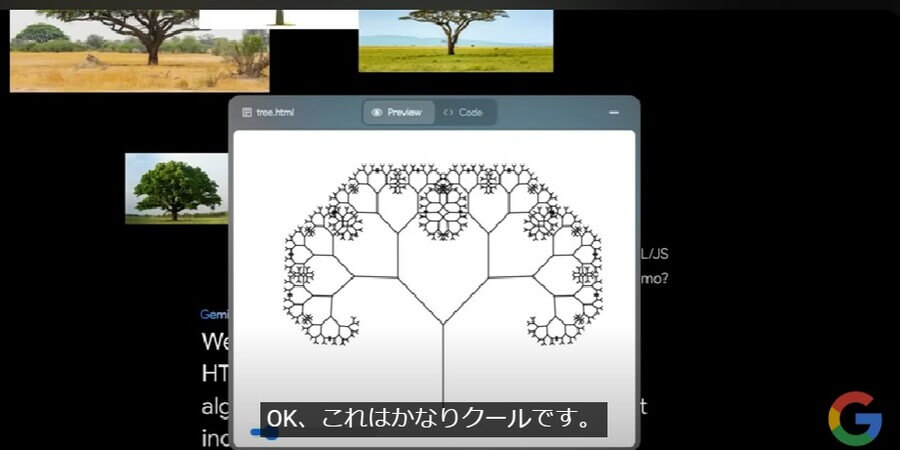 そしてタブを「Preview」から「Code」に切り替えると、上記のフラクタル構造の木の図形を出力するためのJavaScriptのプログラミングコードを表示しました。
そしてタブを「Preview」から「Code」に切り替えると、上記のフラクタル構造の木の図形を出力するためのJavaScriptのプログラミングコードを表示しました。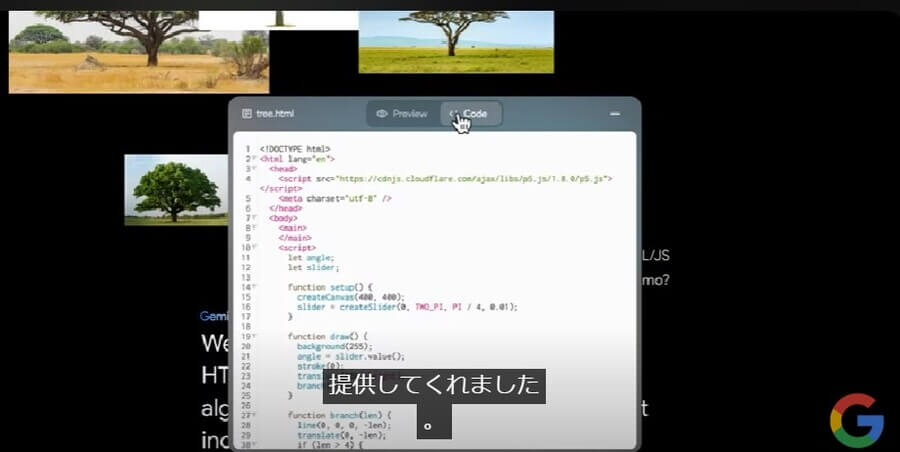
画像や記号を基に推測を行える
Google Geminiを活用すれば、与えられた画像や記号を基に、作品名なども推測できます。たとえば、以下では朝食の画像と指輪の画像を並べて、Google Geminiに映画名の推測をさせています。その結果、2つの画像を認識して映画名の「ティファニーで朝食を」を回答することができました。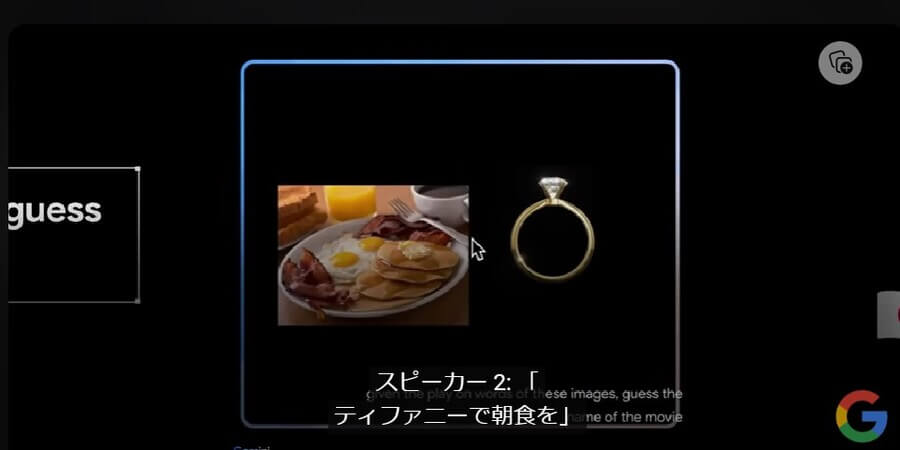
また、以下では月と「↑」マークと城の3つの画像を並べて、Google Geminiに映画名の推測をさせています。その結果、3つを認識して「ムーンライズ・キングダム」の映画名を回答しました。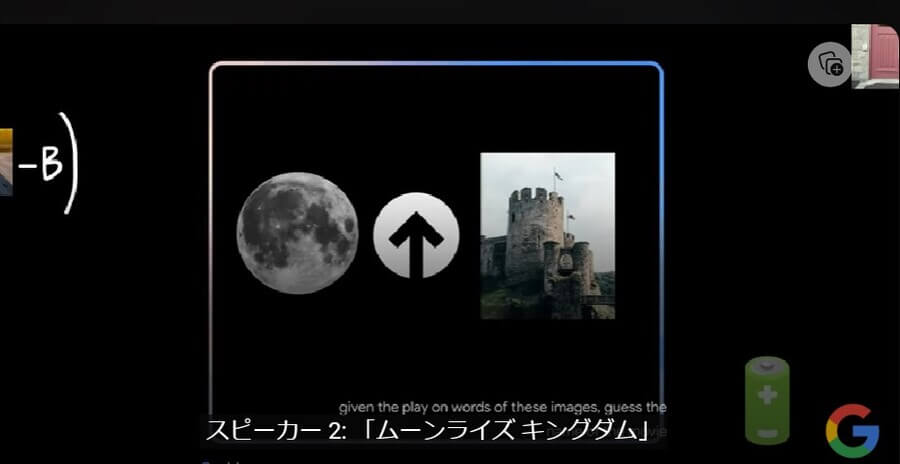
Google GeminiとGPT-4の比較
ここでは、Google GeminiとGPT-4の性能面などの違いを紹介していきます。Google社は、Google Gemini UltraとGPT-4を比較した結果を以下のように示しています。
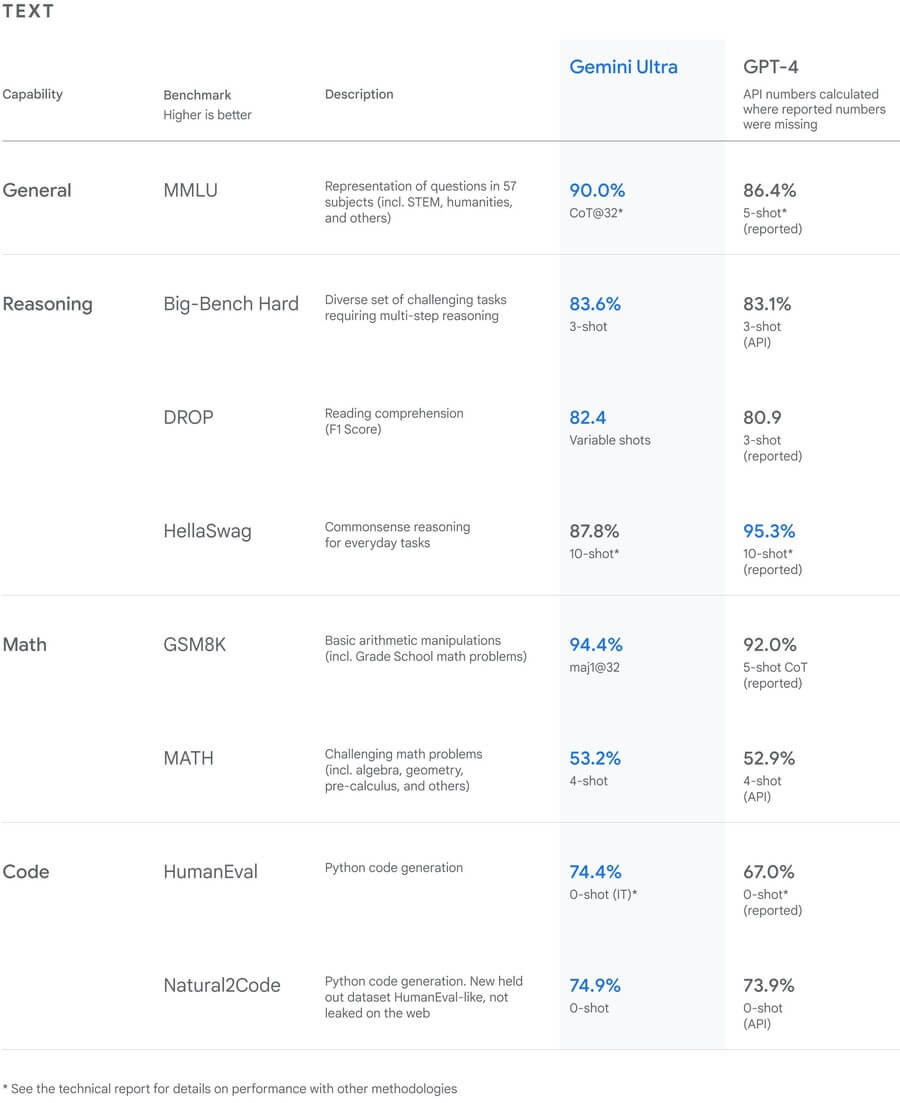
引用元:Google Japan Blog「最大かつ高性能 AI モデル、Gemini を発表 - AI をすべての人にとってより役立つものに」
たとえば、最上部のMMLU(大規模マルチタスク言語理解)は、数学や法律など計57科目における知識と問題解決能力を測る指標です。本指標において、Google Gemini Ultraは90.0%のスコアを記録し、GPT-4の86.4%を上回る結果となっています。
また、ほかにも画像認識や数学的推論など計32項目のうち30項目でGemini UltraのパフォーマンスはGPT-4を上回っていることが示されています。Google GeminiとGPT-4の比較検証の詳細について知りたい方は、Gemini テクニカルレポートも併せてご確認ください。
まとめ:Google GeminiはGoogle社の最新かつ高性能な生成AIモデル
Google Geminiは、2023年12月7日にGoogle社が発表した最新の生成AIモデルです。Gemini Nano、Gemini Pro、Gemini Ultraの3つのモデルがあります。Google Geminiでは、音声と画像を同時に認識したり、画像を認識して問題点を抽出したりできます。
また、画像を認識してプログラミングコードに変換することや、画像・記号を基に作品名などを推測することも可能です。
とくにGemini UltraはGPT-4を上回るパフォーマンスを示していることから、高性能な生成AIモデルとして今後も注目を集めていく可能性があるでしょう。
AI技術はこれからさらに発展していくと予測されているので、早い段階で基本的な活用方法を取り入れておくことが大切です。SEデザインでは、IT分野におけるBtoBマーケティング&セールス支援を行っており、35年以上の実績がございます。業務の効率化や顧客へのアプローチでお困りの際は、お気軽にSEデザインへご相談ください。




