 LLM(大規模言語モデル)とは、膨大なデータ学習に基づいて単語や文章のつながりを適切に予測し、高精度なテキスト生成などができるモデルを指します。「LLMという言葉は聞いたことあるけど、詳しいことはよく分からない」という企業担当者も多いのではないでしょうか。
LLM(大規模言語モデル)とは、膨大なデータ学習に基づいて単語や文章のつながりを適切に予測し、高精度なテキスト生成などができるモデルを指します。「LLMという言葉は聞いたことあるけど、詳しいことはよく分からない」という企業担当者も多いのではないでしょうか。
そこで今回は、LLM(大規模言語モデル)の概要や仕組み、種類、できること、LLMを使ったサービスの例、課題について解説します。
LLM(大規模言語モデル)とは?
はじめに、LLM(大規模言語モデル)の概要と生成AIとの違いについて解説します。
そもそも言語モデルとは?

言語モデルとは、自然言語処理において利用される技術の一つ であり、単語や文章の出現頻度や並び方に対して確率を割り当てたモデルです。膨大なテキストデータを学習したうえで、自然な文章や会話に対しては高い確率を割り当て、文章として不自然になる単語の並び方には低い確率を割り当てます。
たとえば、「明日の天気は?」という文章に対しては、「晴れ」や「曇り」、「雨」などが高い確率で割り当てられます。この場合、「資料」や「機械」といった単語が割り当てられる確率は低くなるでしょう。
日常的な会話のパターンや表現、文章の構造などを言語モデルが学習することで、単語や文章のつながりを適切に予測でき、新たな文章の生成や文章の校正などが可能になります。
LLM(大規模言語モデル)の概要

LLM(大規模言語モデル)とは「Large Language Model」の略であり、言語モデルにおいて以下の3要素を大規模に発展させたモデルです。
- 計算量:コンピューターが計算処理を行う量
- データ量:コンピューターにインプットする文章などの情報の量
- パラメーター数:単語や文章を予測するための確率計算に用いるパラメーターの数
上記3つの要素の大規模化については、米国のAI研究機関であるOpenAIが2020年に「Scaling Laws for Neural Language Models」という論文で説明しています。本論文では、上記3つの要素が増えると、LLMの性能が大幅に高まる「Scaling Law(べき乗則)」が成立することが述べられています。
OpenAIは、実際に上記3つの要素を大規模に発展させることで、高精度なLLM(大規模言語モデル)の構築に成功しています。
出典:Scaling Laws for Neural Language Models
LLM(大規模言語モデル)と生成AIとの違い
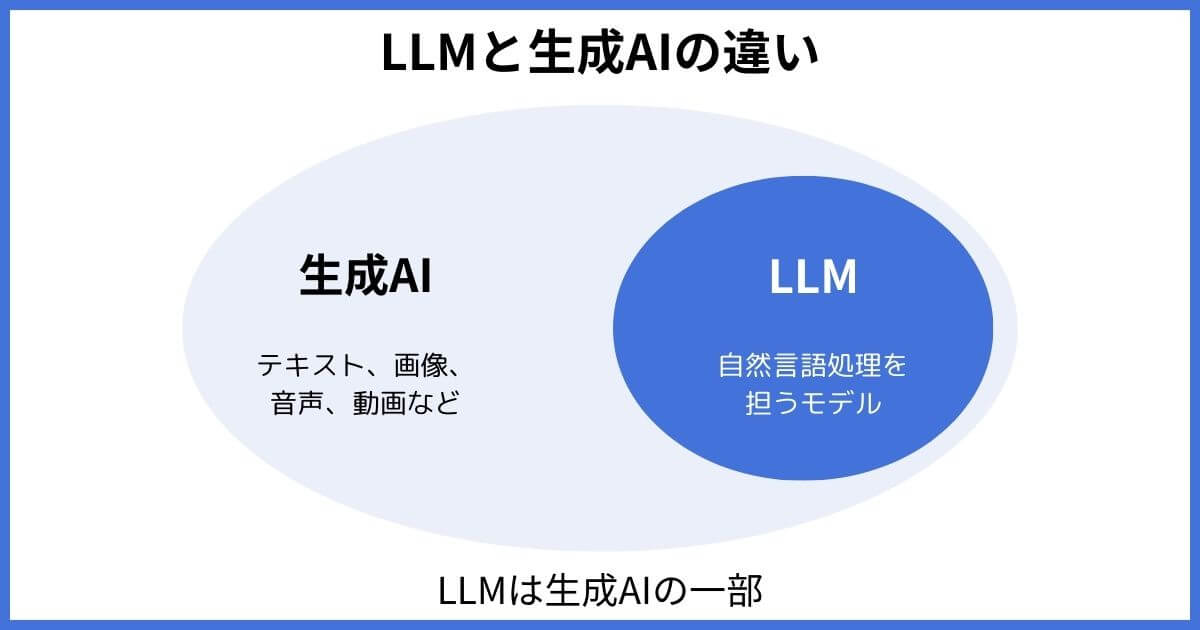
LLM(大規模言語モデル)と混同されやすい用語として、生成AIがあります。生成AIは、テキストや画像、音声、動画などのコンテンツを自動で生み出すAI技術全般のことです。
それに対しLLM(大規模言語モデル)はテキストの生成を行うモデルであるため、生成AIの一部の位置付け となります。LLM(大規模言語モデル)は、膨大なテキストデータを学習して新たなテキストを生成する処理に特化していることから、自然言語処理を担う生成AIであるといえるでしょう。
LLM(大規模言語モデル)の仕組み
LLM(大規模言語モデル)では、まず十分なデータ学習を行うことが重要です。データ学習を行う際は、以下の2段階のプロセスを繰り返し実施します。
1. 事前学習(Pre-Training):膨大なテキストデータを基に、単語や文章のパターンを学習
2. 性能を最適化するための微調整(Fine-Tuning):テストデータを用いたパラメーターの微調整やモデルの妥当性評価
そのうえで、LLM(大規模言語モデル)がプロンプト(入力文)を受けてから文章を生成するまでの流れは以下のとおりです。

- トークン化:プロンプトをトークン(最小単位の単語)に分解し、ベクター化する
- 文脈理解:プロンプト内の各トークン同士の関連性を計算する
- エンコード:特徴量を抽出する
- トークンのデコード:次のトークン(最小単位の単語)を予測する
- 次のトークンの確率を出力:プロンプトの次のトークンの確率を出力する
詳細な仕組みはLLM(大規模言語モデル)の種類によって異なるものの、一般的には上記の流れを繰り返しながらテキストが生成されます。
LLM(大規模言語モデル)の代表的な種類
出典:PRTIMES
続いて、LLM(大規模言語モデル)の代表的な種類として、以下を紹介します。
- GPT(Generative Pretrained Transformer)
- BERT(Bidirectional Encoder Representations from Transformers)
- PaLM(Pathways Language Model)
- LLaMA(Large language Model Meta AI)
- Claude (Anthropic)
GPT(Generative Pretrained Transformer)
GPT(Generative Pretrained Transformer)は、OpenAIが開発したモデルであり、「Transformer」というニューラルネットワークアーキテクチャをベースにしています。
現在は GPT-5 や GPT-5 Pro などが主に利用され、ChatGPT 無料版でもGPT-5 が使えるようになりました。 GPT は ChatGPT に搭載されていることで、LLM のなかでも知名度が高いモデルといえるでしょう。
BERT(Bidirectional Encoder Representations from Transformers)
BERT(Bidirectional Encoder Representations from Transformers)は、2018年にGoogleから発表されたLLM(大規模言語モデル)です。2019年にはGoogleの検索アルゴリズムに実装されています。
BERTのおもな特徴は、単語だけでなく文脈も読み取れる点です。正式名を日本語に訳すと「双方向のエンコード表現」となることからも分かるように、文頭・文末の双方向から文章を解読することで高精度な自然言語処理を実現しています。
PaLM(Pathways Language Model)
PaLM は、2022年に Google が開発したモデルであり、当初は Google Bard に搭載されていました。PaLM のおもな特徴は、約5,400億個ものパラメーター数を誇る点です。豊富なパラメーター数を用いることで、高精度な自然言語処理を実現しています。また、2023年5月には Google から最新モデルとなる PaLM 2 が発表されています。
2024年2月に Bard は「Google Gemini」へ改称され、現在は Gemini 2.5 Pro/Flash等が提供されています。PaLM 系はその後 Gemini 系へ移行し、Google の基幹LLMは Gemini ファミリーに刷新されています。
LLaMA(Large language Model Meta AI)
LLaMA は、2023年に Meta が開発したモデルです。GitHub 等で重み(weights)が広く配布される“オープンウェイト”として公開されています(Meta Llama License)。
厳密な意味でのオープンソース(OSI 定義)ではありません。 LLaMA のおもな特徴は、他のモデルと比べて少ないパラメーター数でありながら同程度の精度を誇る点や、一部の商用利用を除き無料で利用できる点です。
(2024年4月に Llama 3(8B/70B)、2024年7月に Llama 3.1(最大 405B)も公開されています。
Claude(Anthropic)
Claude は Anthropic が提供する LLM で、2024年以降 Claude 3.5、2025年には Claude 3.7 など上位モデルが公開されています。タスク解決やコーディング支援などで高性能を示すモデル群として注目されています。
LLM(大規模言語モデル)で実現できること
LLM(大規模言語モデル)で実現できることとしては、以下のような事項が挙げられます。
- プロンプト内容に応じたテキストの回答
- 情報検索・出典の提示
- 長文テキストの要約
- 文書の誤記チェック
- 多言語の翻訳
- プロンプト内容の続きを予測して出力
- プログラミングコードの記述・バグチェック
LLM(大規模言語モデル)を活用することで、情報検索や文章の翻訳・要約などをスムーズに行えるため、作業効率化につながります。また、チャットボットや検索エンジン(GoogleやBingなど)での活用も効果的です。
たとえば、企業のカスタマーサポートなどにLLMを搭載したチャットボットを導入することで、顧客からの問い合わせ対応の効率化・自動化を実現できます。その結果、オペレーターの適正配置によるコスト削減や待ち時間減少による顧客満足度の向上など、経営上のメリットも享受できるようになるでしょう。
LLM(大規模言語モデル)を使ったサービスの例
©rokastenys/123RF.COM
ここでは、LLM(大規模言語モデル)を使ったサービスの例として、以下の3つを紹介します。
-
ChatGPT
-
Microsoft Copilot(旧Bing Chat)
-
Google Gemini(旧Bard)
ChatGPT
ChatGPTは、OpenAIが2022年11月に公開したAIチャットボットです。ツールの名称にあるとおりGPTが搭載されており、現在はGPT-5が利用可能です。
|
▼ChatGPTの関連記事 ・ChatGPT とは?概要や仕組み、使用方法、メリットなどを解説 |
Microsoft Copilot(旧Bing Chat)
Microsoft 社が 2023年に公開した対話型 AI サービスで、検索・ブラウジングと連携して利用できます。
現在は「Microsoft Copilot」として提供され、GPT-4 系のモデルを基盤に、画像・テキストなどのマルチモーダルな入出力にも対応します。企業利用では商用データ保護(プロンプトや応答・Graph データを基盤モデルの学習に利用しない)も整備されています。
|
▼Microsoft Copilot(旧Bing Chat)の関連記事 |
Google Gemini(旧Bard)
Google が 2023年に公開した対話型 AI サービス「Bard」は、2024年2月に「Gemini」へ改称されました。現在は Gemini 2.5 Pro/Flash などが提供され、高度な自然言語処理やコーディング支援が可能です。
|
▼Google Gemini(旧Bard)の関連記事 |
LLM(大規模言語モデル)の課題
 LLM(大規模言語モデル)は、情報検索や翻訳、テキストの要約などに役立つ一方で、いくつか課題も存在します。おもな課題は以下のとおりです。
LLM(大規模言語モデル)は、情報検索や翻訳、テキストの要約などに役立つ一方で、いくつか課題も存在します。おもな課題は以下のとおりです。
- モデルによって精度の違いや学習データのバイアスがある
- 機密情報や個人情報の漏えいリスクがある
- 出力結果が正確でない場合がある
モデルによって精度の違いや学習データのバイアスがある
LLM(大規模言語モデル)では、モデルによって回答の精度が異なったり、学習データのバイアスによって偏った回答が出力されたりする可能性があります。
たとえば、学習データに特定の国・地域の生活習慣や宗教などが多く含まれている場合、回答結果も偏った内容になる場合が考えられます。また、「男性は料理が苦手」「女性は数学が苦手」といった偏見が入り込んでいる可能性もあるでしょう。
機密情報や個人情報の漏えいリスクがある
LLM(大規模言語モデル)では、機密情報や個人情報の漏えいリスクがある点も課題です。LLMを利用する際に、ユーザーが機密情報や個人情報を入力した場合、それらの情報が学習されて第三者への情報漏えいが生じるリスクがあります。
チャットボットなどを使う時は、自身の個人情報や所属企業の機密情報を入力しないよう、ユーザー側の注意も求められるでしょう。
出力結果が正確でない場合がある
LLM(大規模言語モデル)では、不正確な情報をあたかも正しい情報かのように回答する「ハルシネーション」が生じる可能性がある点も課題です。プロンプトに対する回答として確率的に高い単語や文章を並べる仕組みであるため、回答の正確性までは保証されていません。
そのため、一見すると正しいと思えるような返答でも、必ず人間の目で事実関係を確認するようにしましょう。
また、日本語などの英語以外の言語の場合、回答精度が落ちる傾向があります。OpenAIの調査によると、GPT-4の回答精度は英語が最も高く、日本語は調査対象の27言語中16番目の精度となっています。
LLM(大規模言語モデル)によって高度なテキスト生成が可能
LLM(大規模言語モデル)は、言語モデルのなかでも計算量やデータ量、パラメーター数を大規模化したモデルであり、高精度なテキスト生成や翻訳などが可能です。LLMにはOpenAIが開発したGPTやGoogleが開発したPaLMなどがあり、それぞれChatGPTやGoogle BardなどのAIツールで活用されています。
LLMを利用することで、情報検索や長文テキストの要約、多言語の翻訳、コーディングといったさまざまな作業を効率的に行えます。
ただし、出力結果に不正確な情報が含まれる可能性がある点や、機密情報・個人情報の漏えいリスクがある点には注意しましょう。
AI技術はこれからさらに発展していくと予測されているので、早い段階で基本的な活用方法を取り入れておくことが大切です。SEデザインでは、IT分野におけるBtoBマーケティング&セールス支援を行っており、35年以上の実績がございます。業務の効率化や顧客へのアプローチでお困りの際は、お気軽にSEデザインへご相談ください。



